End-to-end object detection with transformers
Contents
Motivation
- 首篇将 transformer 用在 detection 任务上的工作
- 使用 transformer 来做 detection 任务,有什么优势的地方?
Method
-
总体架构是一个 encoder-decoder, 并且和之前的检测方法不同,DETR 可以直接输出对所有检测框的预测结果,没有后处理的步骤 (NMS).
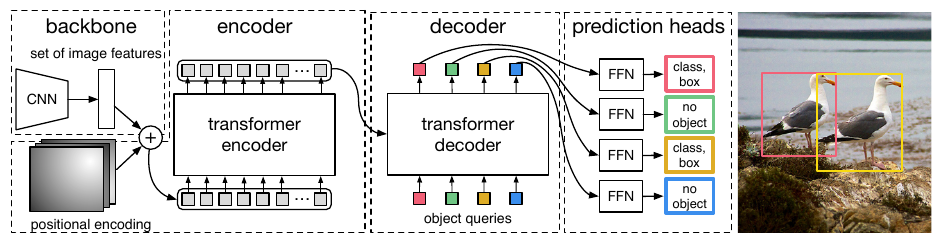
-
首先是 encoder 部分,输入图片经过 CNN 得到 dxHxW 的 feature map, 然后将每个 grid 作为一个向量,组成 encoder 的输入序列。为了保留每个 grid vector 的空间位置信息,会加上固定的 position encoding. 然后是一般的 encoder 处理,self-attention + norm + FFN (Feedforward network). Encoder 和 Decoder 的结构如下:
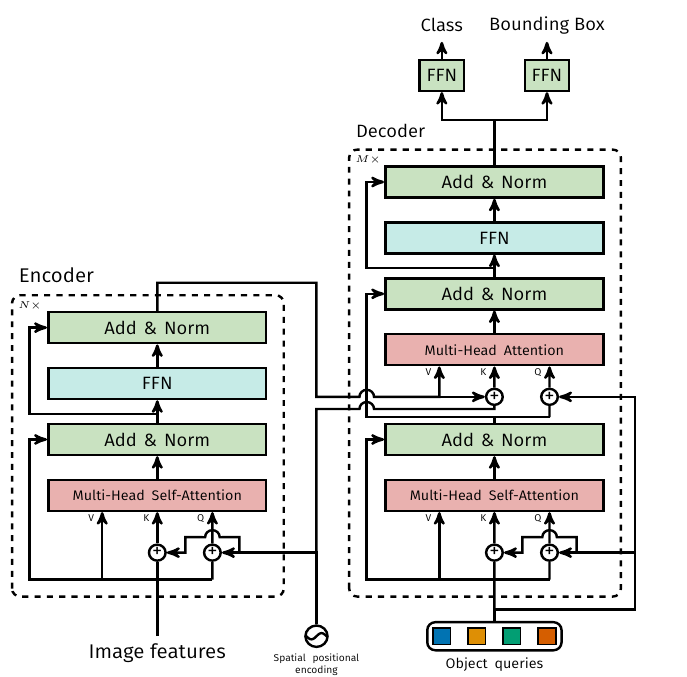
-
在 Decoder 部分,会输入 N 个 object query, N 的数量设定为远大于图片中最多检测目标的数量。每个 object query 实际是一个需要学习的 embedding, 他们起到的物理意义,我看一些文章的说法是类比于传统目标检测的 anchor, 也就是学到了目标的位置信息 (这里还是有一些疑惑).
-
Set prediction loss: loss 的设计是 DETR 的重点,在 DETR 中,目标检测任务被 formulate 成两个集合的匹配问题。首先模型会预测 N 个结果,而 ground truth 包含 M 个结果,并且 N»M. 首先让预测和 ground truth 集合大小一致,即在 ground truth 的集合中 pad N-M 个 no-object class. 然后这里的优化目标就是要让预测的集合与 ground truth 的集合匹配。
第一步是利用匈牙利算法,找到一个匹配,也就是找到预测集合的每一个 object query 对应的 ground truth 集合中的一个结果
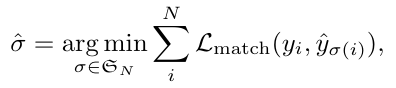
具体这个 L_match 的定义为,c_i 是 ground truth 集合中,第 i 个元素的标签,而 σ 则是一种匹配,利用这个 match loss 来找到 optimal 的匹配:
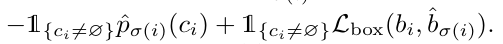
第二步是根据找到的匹配,来计算 loss, 这个 loss 是指对物体的类别预测、对 bbox 的回归的修正:
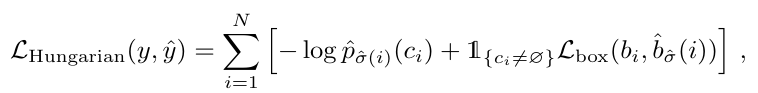
对 bounding box 的 loss 具体是:
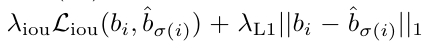
对坐标值进行 L1 的约束,并且考虑不同大小的 bbox 可能在 L1 上差距较大,而实际大的 bbox 和小的 bbox 的相对误差是差不多的,所以通过 IoU 加上了一个约束
Comment
- 对应于传统目标检测的 RoI 特征,在 DETR 中是哪部分包含了检测物体特征和信息?似乎是每个 object query 看作一个 anchor, 它可以去和全局的 image 信息 (由 encoder 编码) 去求 attention 的响应,这样每个 object query 通过 multi-head attention 和 ffn 后,会计算得到一个 feature, 这个 feature 就包含了物体的 RoI 信息。
- Encoder 输出的结果是一个序列还是一个整体的表征?一个序列是说输入是 HxW 个 grid vector, 输出也是 HxW 个 grid vector.
Ref
Author Li Xunsong
LastMod 2021-07-16