PPDM: parallel point detection and matching for real-time human-object interaction detection
Contents
Motivation
Method
总体框图
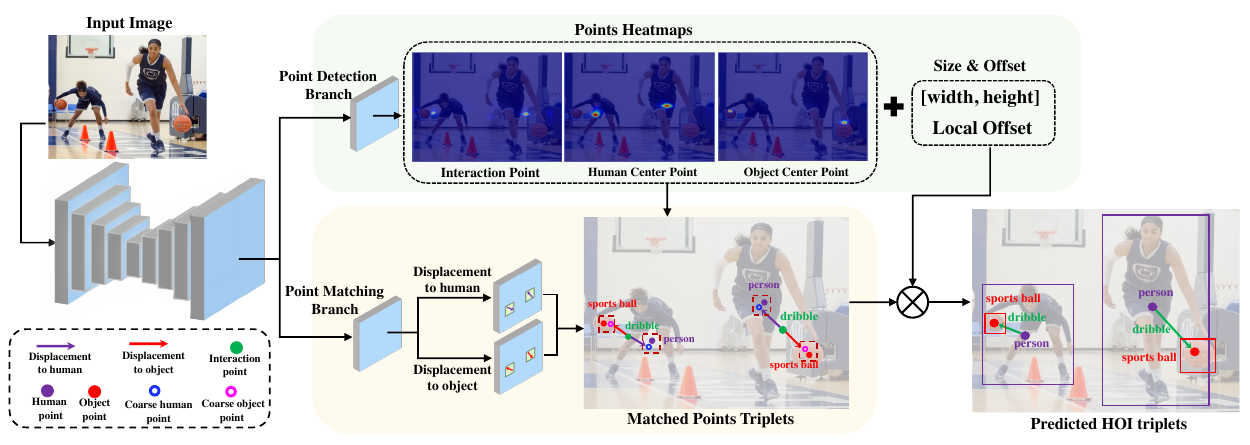
Point-dection
预测三种 box: human,object,intertion box. 每个 box 预测他们的中心点、size 以及偏移。对于中心点的预测,转换成 key-point estimation 的做法,将每个 ground truth 点转换成一个 heatmap, 然后预测的任务就变成估计这个 heatmap. 对于 heatmap 的预测,定义 loss 为:
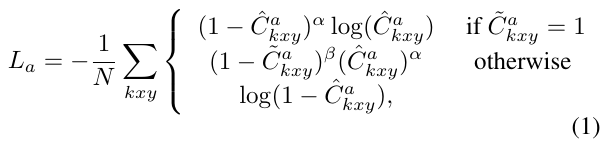
Point-Matching
根据 interaction point, 找到与它匹配的 human box 和 object box. 这里学习的目标,是对 ground truth 中的每个 interaction point, 也就是图片中每一个 HOI triplet, 学习其相对于 human point 和 object point 的位移。将图片的 feature map 通过 3x3 conv, ReLU, 以及 1x1 conv, 得到 2x(H/d)x(W/d) 的预测结果,这里的 channel 2 就是代表分别在 x 方向和 y 方向的偏移。定义 displacement loss 为:
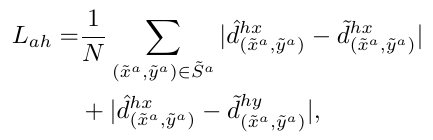
这里的含义就是对于每个 ground trutch 中的 interaction point, 有一个位置坐标 (x, y), 对应找到在预测的 2x(H/d)x(W/d) 的 map 的位置的预测,预测出的位移量要和 ground truth 得到的位移量一致。
得到每个 interaction point 的相对于 human 和 object 的位移后,需要和预测的 human point 和 object 进行匹配,原则是,human/object point 要尽可能和 interaction point + displacement 得到的位置一致,并且 human/object 的 confidence score 要尽可能高。于是对每个 interaction point, 选择的 matching human/object point 应该是:
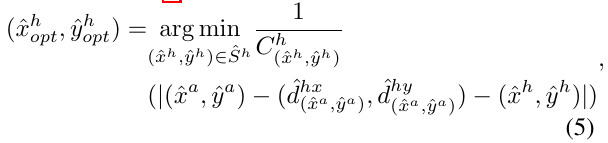
Inference
Inference 阶段,首先是得到 human/object/interaction 各自的 heatmap, 在这个 heatmap 上可以得到若干检测到的 point. 然后再根据 point-matching, 对每个 interaction point, 去找到它匹配的 human 和 object point, 然后再计算匹配的 triplet points 的 box.
Comment
Ref
- Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
Author Li Xunsong
LastMod 2021-08-03