Adaptive interaction modeling via graph operations search
Contents
Motivation
- 之前建模 action 中的 interaction 的工作都是设计了 fix 的 structure 来建模这些 interaction, 但视频中的 interction 具有不同的复杂性和特性,有些是场景的变化相关,有些是物体之间的复杂交互,所以为了建模这些不同性质的 interaction, 需要设计能够自适应调整的网络结构。
- 这篇文章定义了几种基本的图运算来建模视频中的 interation, 然后使用 NAS 来搜索建模不同视频 interaction 所需要的基本图运算的结构,来达到他们针对不同性质的 interaction 自适应调整网络结构的目的。
Method
定义的几种 graph 的基本操作
- Feature aggregation
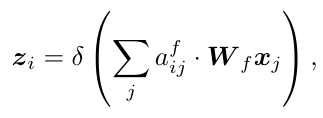 类似于 GAE, αij 表示结点 i 和结点 j 之间的 affinity (近似). 每个结点通过建模与其他结点的依赖关系来增强自身的特征表达。
类似于 GAE, αij 表示结点 i 和结点 j 之间的 affinity (近似). 每个结点通过建模与其他结点的依赖关系来增强自身的特征表达。 - Difference propagation
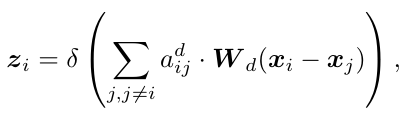 显式地将两个结点之间特征的差异进行 message propagation. 这样来建模 objects 的变化或者差异。
显式地将两个结点之间特征的差异进行 message propagation. 这样来建模 objects 的变化或者差异。 - Temporal convolution
前面两种操作没有考虑结点的时间顺序,这里 temporal convolution 就是为了显式地建模时序上的信息。具体操作是,对于第 t 帧的结点 i, 找到它在每帧上面最近的结点(这里的近是通过结点之间 inner product 来度量的),然后将他们组成一个序列:
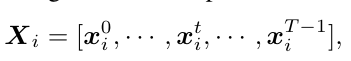 在这个序列上使用 temporal convolution, 得到的这个特征作为结点 i 在 temporal 上的信息:
在这个序列上使用 temporal convolution, 得到的这个特征作为结点 i 在 temporal 上的信息:
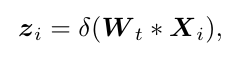
- Background incorporation
这里认为 background 的信息对于识别 interaction 也是有帮助的,例如 object 可能会与 background 产生 interaction. 所以对每一帧的结点 i, 计算它和这一帧的 feature map 不同 grid 特征的响应,然后做聚合:
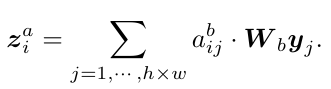
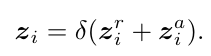
- Node attention
由于会检测出上百个结点,但不是所有结点对于识别 interaction 是有贡献的,因此使用 attention 的方法来削弱那些 outlier 的结点。这里认为 outlier 的结点是那些有很少的相似结点,并且在位置上和其他结点的对应关系不是常规的,依据这个规则来设置每个结点的 attention weight, 公式如下:
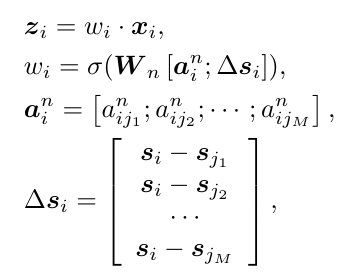 这里 w_i 是每个结点的 attention weight, w_i 的计算是通过 a_i 和 s_i 来计算的。a_i 是结点 i 和它前 M 个相似的结点的 affinity score, s_i 是结点 i 和它前 M 个相似结点的相对位置。把这两个信息作为输入,来输出每个结点的 attention weight, 这和之前对 outlier 结点的定义是一致的。
这里 w_i 是每个结点的 attention weight, w_i 的计算是通过 a_i 和 s_i 来计算的。a_i 是结点 i 和它前 M 个相似的结点的 affinity score, s_i 是结点 i 和它前 M 个相似结点的相对位置。把这两个信息作为输入,来输出每个结点的 attention weight, 这和之前对 outlier 结点的定义是一致的。
结构搜索
- 注意每种操作都是将输入 x_i 转换成 z_i
- 在结构搜索的时候使用了 DARTS, 从一个 cell 到另一个 cell 得到的结果 (intermediate representation) 是上面定义的几种基本图的操作的 softmax 的加权和:
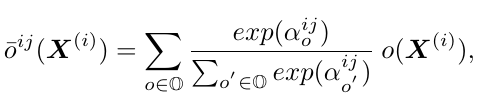 而这个加权的系数 α_o 由原始的输入视频特征决定:
而这个加权的系数 α_o 由原始的输入视频特征决定:
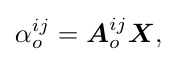 这样就达到论文最初的动机,希望根据对不同视频中的 interaction 使用不同的网络结构去建模。而最后搜索出来的结构是对所有操作的系数取 argmax:
这样就达到论文最初的动机,希望根据对不同视频中的 interaction 使用不同的网络结构去建模。而最后搜索出来的结构是对所有操作的系数取 argmax:
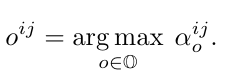
- 为了防止在搜索结构的时候只偏向某几种 operation, 再加了一个 diversity regularization:
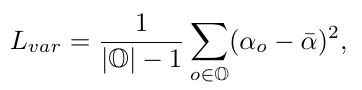
Comment
-
graph 中的结点是每帧的 ROI 吗?是
-
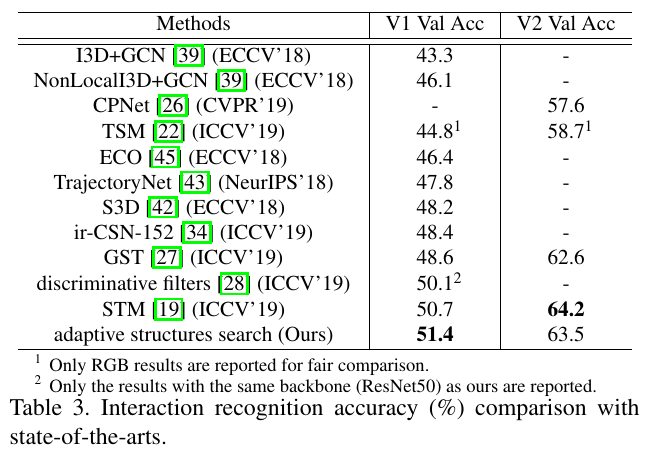
实验是在 something-something 上面进行的,实验结果:
-
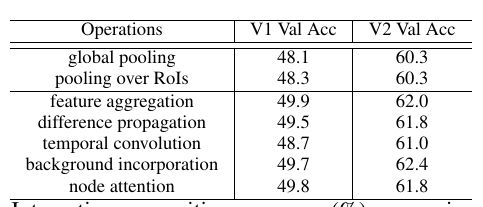
几种 basic graph operation 的实验结果:
Ref
Author Li Xunsong
LastMod 2021-07-10