Detecting Unseen Visual Relations Using Analogies
Contents
Motivation
- 直言要解决 HOI 中的组合问题:individual entities are available but their combinations are unseen at training.
- 之前的一些方法是单独检测 entity 和 predicate, 然后再把结果组合起来。但这样单独检测的问题是,visual interaction (predicate)是很难单独被表征的,它往往依赖于物体,并且随着物体的差异会有很大的 appearance variance. 例如检测 ride 这个动作的 detector 是很在 visual difference 很大的 relation: “person ride horse” 和 “person ride bus”.
- 另一种方法是检测整个 triplet, 这里称为 visual phrase. 但这样就需要每个 triplet 都有足够的训练样本来训练每个 visual phrase detector.
- Unseen relations and transfer learning.
Method
-
visual phrase embedding: 对于 subject, object, predicate 以及 triplet 都会有这样一个 embedding, 它是将 visual embedding 和 word semantic embedding 结合到一起到一个 embedding space.
-
Model overview:
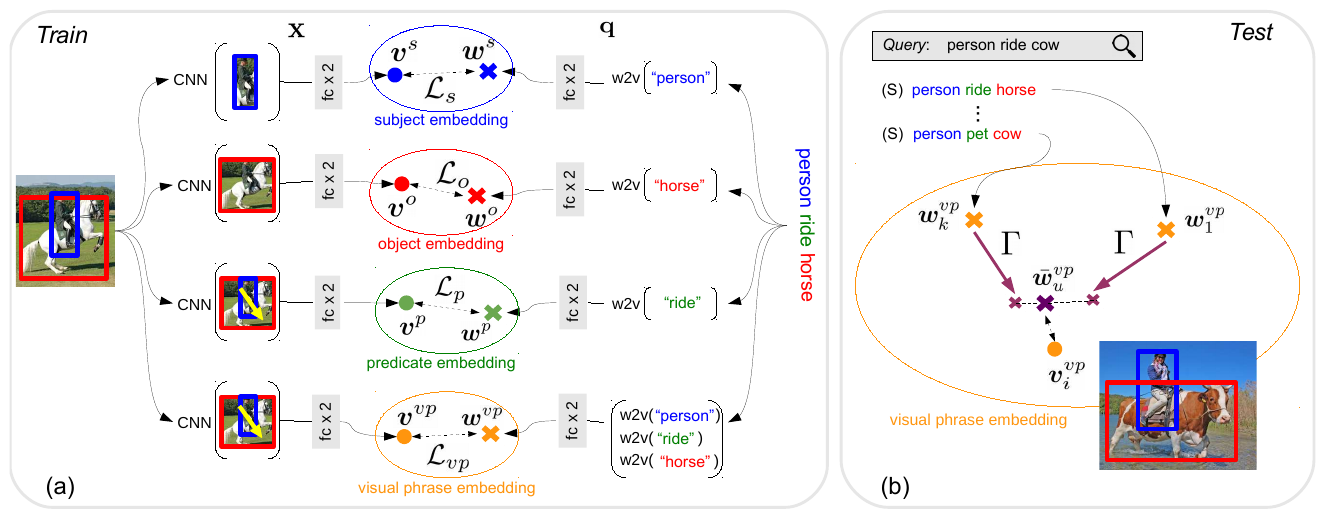
-
将 visual phrase embedding 迁移到 unseen triplets 上。这种迁移可以达到将 knowledge 迁移到 unseen 的组合上的目的。
unseen triplet 的 visual phrase embedding 是怎么得到的?
-
整体的思路,对于一个 HOI label, 它是一个 triplet, 由
三部分组成。这篇文章的主要目标是学到每个 triplet 的 visual-phrase embedding, 这个 embedding space 中既有 language 的 knowledge, 也有来自图片样本的 visual knowledge. 而对于没有见过的 triplet, 就将从见过的 triplet 学习到的 visual embedding 迁移到这些没有见过的 triplet 上。 -
对于 unseen 的 triplets, 只有在测试的时候会给出样本,在训练的时候是没有样本的,只有一个标签,即这个 triplet 的描述。
-
对于 senn 的 triplets 的训练和测试:
-
训练:拉近 triplet 的 visual feature 和其 language feature 的距离,拉远和无关 triplet 的 language feature 的距离:
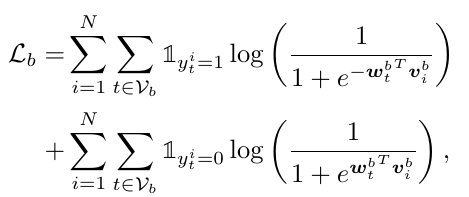
-
测试:直接度量每个 triplet 的 language feature 和 candidate pair 的 visual feature 之间的距离:
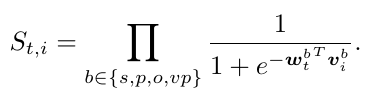
-
需要注意的是,从图中也可以看出,每个 triplet 会有 4 中 language feature, 分别是 subject, object, predicate 以及整体的 visual phrase embedding, 用到的 visual feature 也不相同,但在最后测试的时候只会用到 visual phrase embedding. 单独的这几个 embedding 学习的含义和作用是什么?embedding 之间的参数是共享的吗?
-
-
到 unseen triplet 的迁移
-
整体的形式
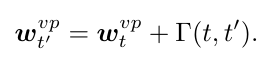 这里 t' 是 unseen triplet, w^vp 表示 visual phrase embedding, 最后的这一项就是用来捕获两个 triplet 之间的差异,来将 seen triplet 迁移到 unseen triplet.
这里 t' 是 unseen triplet, w^vp 表示 visual phrase embedding, 最后的这一项就是用来捕获两个 triplet 之间的差异,来将 seen triplet 迁移到 unseen triplet. -
\(\Gamma\) 的具体形式:
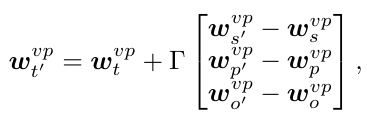 它的输入是 subject, object, predicate 的 visual phrase, 尽管 triplet t' 是 unseen 的,但将它拆分成的这三个部分都是 seen 的。并且这里只是 language faeture, 如果两个 triplet 分别是 “(person, ride, horse)” 和 “(person, ride, camel)”, 那么输入就会变成:
它的输入是 subject, object, predicate 的 visual phrase, 尽管 triplet t' 是 unseen 的,但将它拆分成的这三个部分都是 seen 的。并且这里只是 language faeture, 如果两个 triplet 分别是 “(person, ride, horse)” 和 “(person, ride, camel)”, 那么输入就会变成:
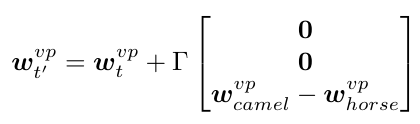
-
只 transfer 彼此相似的 triplet
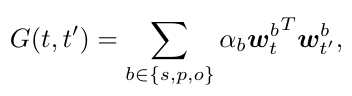 度量 triplet 之间的相似性,具体就是比较每个 subject, object, predicate 之间的相似性,然后做一个加权求和,得到 triplet 之间的相似性,然后选出相似性最大的几个 triplet 来做 transfer
度量 triplet 之间的相似性,具体就是比较每个 subject, object, predicate 之间的相似性,然后做一个加权求和,得到 triplet 之间的相似性,然后选出相似性最大的几个 triplet 来做 transfer -
\(\Gamma\) 的学习 这个 \(\Gamma\) 的学习是在训练集上进行,不涉及到测试的 unseen triplet. 对于 training batch 中的每个 triplet t', 找到一堆相关的 triplet t 组成 pair. Q 是整个 (t, t') 的 pair. 优化的 loss function 是:
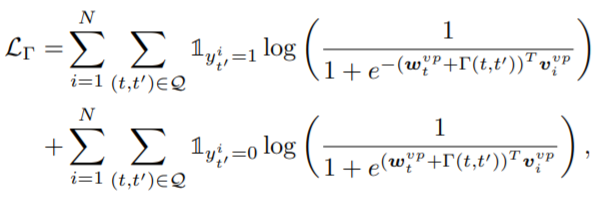 vivp 是 target triplet 的 visual feature, \(w_{t}^{vp}+\Gamma(t,t')\) 是从 triplet t 迁移过来的 visual phrase embedding. 这个 loss 的目的是让 targe triplet 的 visual feature 和它从 match 的 triplet t 迁移得到的 visual phrase feature 尽可能接近,而远离不 match 的 triplet 迁移。
vivp 是 target triplet 的 visual feature, \(w_{t}^{vp}+\Gamma(t,t')\) 是从 triplet t 迁移过来的 visual phrase embedding. 这个 loss 的目的是让 targe triplet 的 visual feature 和它从 match 的 triplet t 迁移得到的 visual phrase feature 尽可能接近,而远离不 match 的 triplet 迁移。 -
测试时一个 unseen triplet 的表征:
 unseen triplet u 从与他相邻的几个 triplet 的 visual phrase embedding 中迁移并加权得到
unseen triplet u 从与他相邻的几个 triplet 的 visual phrase embedding 中迁移并加权得到 -
训练策略 先训练 embedding function, 包括 subject, object, predicate 和 visual phrase. 然后固定 s, o, p, fintune vp. 这时再开始训练 \(\Gamma\), 并且训练 \(\Gamma\) 的 loss 只用于更新 \(\Gamma\) 函数,而不参与到 visual phrase embedding 的参数更新中。
-
Comment
Ref
- 和 Learning to detect human-object interactions with knowledge 这篇有点类似,都借助了外部的 language knowledge.
- Chao-wacv-2018-learning
Author Li Xunsong
LastMod 2021-05-21