Learning to detect human-object interactions with knowledge
Contents
Motivation
- 关注 HoI 的长尾分布问题
- Motivation: HOIs contains intrinsic semantic regularities -> Modeling the underlying regularities among verbs and objects.
Method
- 整体的框架:
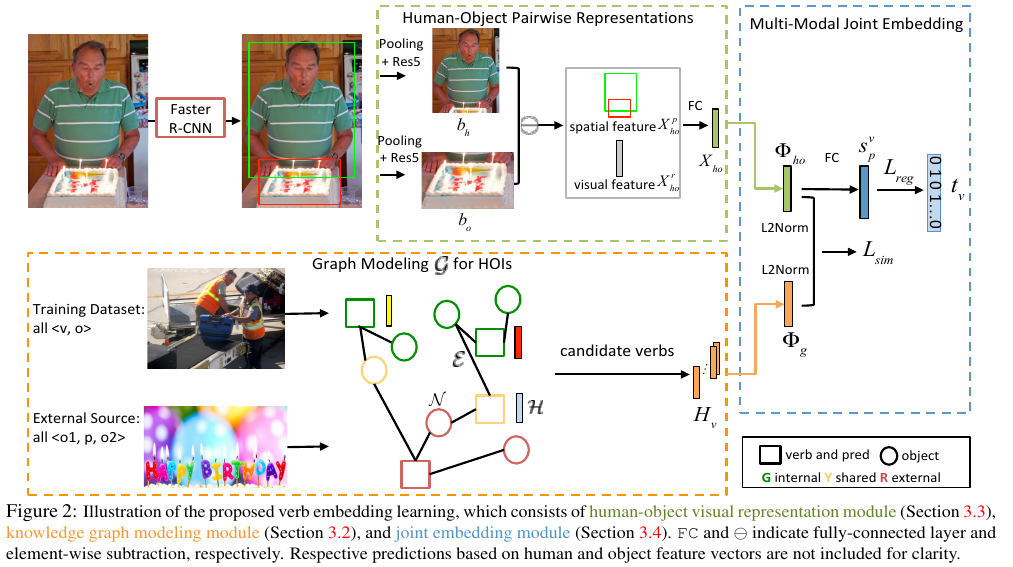
- Knowledge graph 的构建:结点就是 HOI labels 中 verb 和 object 的词语,特征是 Glove 中得到的 semantic embedding. 结点的连接根据 verb 和 object 是否是一个 HOI label, 是的话就连接起来,同时还引入了外部的一个 visual relation dataset 来构建(不清楚这里只是添加了额外的边,还是添加了额外的结点)。
- 学习:
-
从图片里抽取 human-object pair 的 spatial feature 和 visual feature, 但这里做法似乎有一些特殊,之前没有见过。从文中的描述来看,似乎是先对 human 和 object 的 visual feature 进行 concat, 得到 X^r, 然后提取他们之间的 relative location configuration X^P, 然后又对这两种特征做了一个相减的操作?总之这里最后得到的特征是用来描述每个 pair 之间的 interaction 的,提取特征的做法说是参考的 Zhang-cvpr-2017-visual.
-
knowledge graph 的参数和 visual 特征提取网络的参数是联合训练的。在 kowledge graph 经过 GCN 操作得到更新后的 node representation 后,用其中的 verb node representation 和提取到的 pair 的 visual interaction feature 进行 similarity 的度量,这样保证 visual 的信息和 word semantic 的信息相互影响。从后面的 visualization 实验上来看,这种联合训练对最后 verb 的 node representation 是有影响的,它可以去除语言上的一些 bias, 例如 brush with 和 drink with 在原始的 glove embedding 上是相近的 (因为都有 with 这个单词),但经过 learning and update 之后,drink with 的结点和 sip 这个结点相近了。
-
整个训练的 loss 包括三个部分:
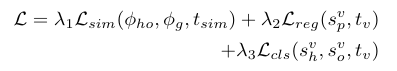 第一个 sim 就是度量视觉上 pair 的 verb 表征向量(visual, spatial)和 knowledge graph 中的 verb 结点向量的相似性,具体为:
第一个 sim 就是度量视觉上 pair 的 verb 表征向量(visual, spatial)和 knowledge graph 中的 verb 结点向量的相似性,具体为:
 第二个 reg 是直接对 pairwise 的 verb embedding (视觉上的)预测,用 cross entropy 来约束
第三个 cls 是单独对 human 和 obejct 得到的特征进行动作预测的 cross-entropy loss
第二个 reg 是直接对 pairwise 的 verb embedding (视觉上的)预测,用 cross entropy 来约束
第三个 cls 是单独对 human 和 obejct 得到的特征进行动作预测的 cross-entropy loss -
Infrence:
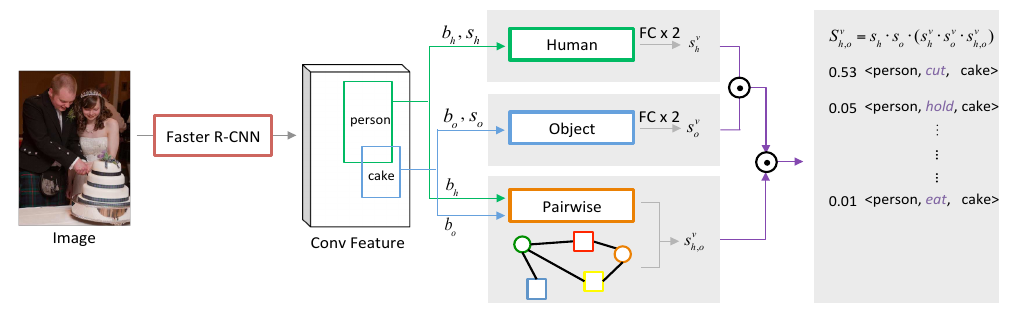
sh,o^v = s_p^v * softmax(cos(φho, φg))
-
Comment
- 这种语义的 regularities 是指 ride 和 sit_on 这两种语义上相近的 verb, 在得到的视觉特征上也应该是相似的吗?
Ref
- Visual translation embedding network for visual relation detection
Author Li Xunsong
LastMod 2021-05-18