Towards compositional action recognition with spatio-temporal graph neural network
Contents
Motivation
- 将动作中的每一帧看作一个 scene graph, 通过这个 scene graph 可以得到动作中物体和人之间的交互关系,将这些 intermediate 的关系组合到一起,再去识别动作,这在 Ji-cvpr-2020-action 中被提出。
- 这篇文章的主要贡献是使用了不同的 GNN 来 encode 每一帧的 scene graph, 对整个 framework 进行了一些改进
Method
- Action genome 数据集
- 视频是长视频,一个视频中可能包含了对人动作的多个标注,共有 157 个动作,在标注的时候会给出动作的起止时间
- 对视频中的人和物体给了 bounding box 的标注,并且对 human-object 之间存在的 relation 也进行了标注
- 一共有 36 种不同的 object 类别,25 种不同的关系,同一个 human-object 之间可能存在多种 relation
- 他们这里的输入并不是 raw video, 而是已经标注好的每一帧的 scene graph. 所以视频中的特征他们并没有利用
- 图的构建:
- Relation matrix: \(M \in R^{|O|\times|R|\), 如果物体 o 与 human 具有某种 relation, 那么这个关系矩阵中对应 entry 的值就为 1.
- Node: 将每种物体对应一个 embedding (look-up node features),这样得到一个 node embedding matrix \(E_{node} \in R^{|O|\times |O|\bullet|R|}\).
- Edge: 这里的边应该只有 object 和 human 之间的连接,每两个结点之间会有 R 种类型,也就是 R 种类型的边,这样每条边可以用一个长度为 R 的 binary vector 来表示,然后进一步通过一个 linear transformation 来表示这个边
- Graph encoder:
这里实验了几种不同的 graph encoer, 需要考虑到这里同时存在 node feature 和 edge feature. 这里的 graph encoder 我们可以参考。
- GINE:
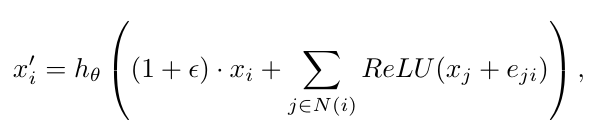
- CGConv:

- NNConv:

- GINE:
- Readout Readout 需要经过 message passing 后的 scene graph 变成一个 vector, 来表示这一个 graph. 论文同样实验了三种方式:Person. 将 human node 的 resultant message 作为 scene graph 的表征。MEAN. 对图里所有结点的 resultant message 取平均 MAX. 对图里所有结点的 resultant message 做 max pooling.
- Temporal reducer 对每个 video clip, 有一个序列的 scene graph, 在得到每个 scene graph 的 descriptor 后,在时间维度上进行聚合。考虑了两种方式,temporal pooling 和 RNN.
Comment
- 这个任务中,human-object 之间的 relation 是预先定义好的
Ref
Author Li Xunsong
LastMod 2021-09-07