Detecting human-object interactions via functional generalization
Contents
Motivation
- HOI 任务中,所有可能的 HOI 会随着 object 和 predicates 的数目增长而指数性地增长,但数据集中的训练样本并不能提供全部可能的 HOI, 这导致 HOI label 会有长尾分布的问题。
- 功能相似的物体,会出现在相近的 interaction 中。例如,eat <burger, hot dog, sandwitch, pizza>, 后面的这些物体都是可以说是功能相近,所以他们都可以出现在 eat 这个动作中。
- 这篇文章提出一种类似于数据增强的方式,找到很多“功能相似”的 object, 这些 object 可能不在数据集中出现,然后用这些 object 的信息去训练同一个类别的 HoI classifier. 在判定物体 “功能相似” 时,引入了一些先验知识 (common sense), 最后将功能相似定义为物体的 visual appearance 和 semantic representation 结合到一起来判定物体之间是否具有相似的功能。如果具有了相似的功能,那么物体就可能出现在同一个 HoI label 中。
Method
- 框图:
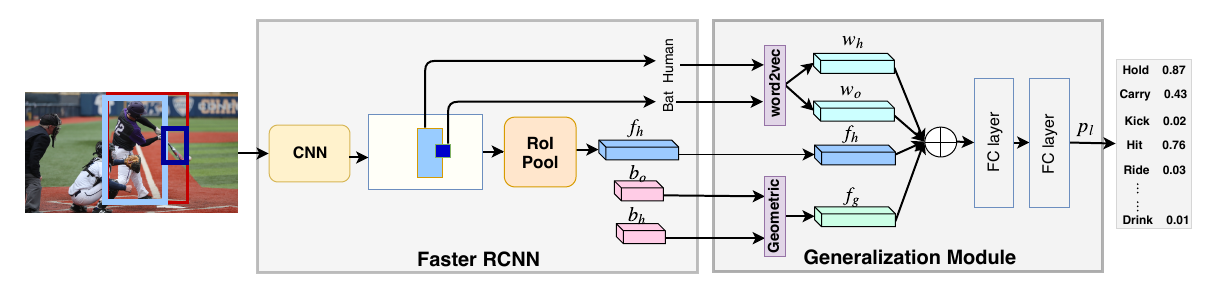
- generalization 模块:
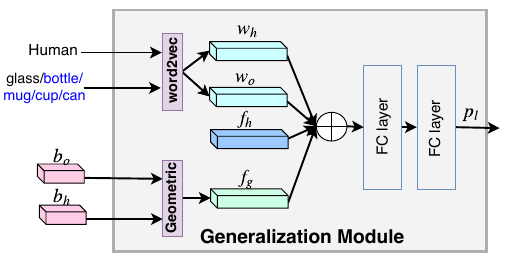 这里将相似的物体进行替换,替换的只是物体 word embedding 的输入部分,其他部分的输入保持不变,仍是从 HoI 图片样本中得到的。#+HUGO_BASE_DIR: /mnt/c/Users/lixun/Documents/xssq-blog
这里将相似的物体进行替换,替换的只是物体 word embedding 的输入部分,其他部分的输入保持不变,仍是从 HoI 图片样本中得到的。#+HUGO_BASE_DIR: /mnt/c/Users/lixun/Documents/xssq-blog
Comment
- 如何定义功能相似的 object?
- 如何做到 zero-shot?
- 提到了对 dataset bias 的定义 (Zhao-emnlp-2017-men),构建了一个 bias dataset. 具体而言,考虑一个 <object, predicate> pairs 的集合,然后对每个 pair q_i, 考虑两种情况:1. bias against the pair 2. bias towards the pair. 第一种情况,将数据集中全部包含 pair q_i 的样本去掉(相当于从来没有看见过 q_i),然后保留所有包含物体 o_i 的样本(物体 o_i 在其他的动作 (predicate) 之中)。第二种情况,去掉所有包含物体 o_i 的样本,除了是 q_i 这个 pair 的(相当于只见过物体 o_i 出现在 q_i 这个 pair 中)。
Ref
Author Li Xunsong
LastMod 0001-01-01