0. Matching Network for One Shot Learning
1. Summary
This paper is a metric-based method for few-shot learning task. It uses attention mechanism and considers to embed the whole support set into feature space not just a single sample in the support set. Given a query image, the predict output is the weighted sum of the samples in the support set.
2. Reaserch Object
Learning from a few examples, one-shot learning
3. Problem Statement
Train a classifer, test with a few(eg. 1-shot, 5-shot) queries(images) of unknown classes.
4. Methods
attention, memory
- overall architecture
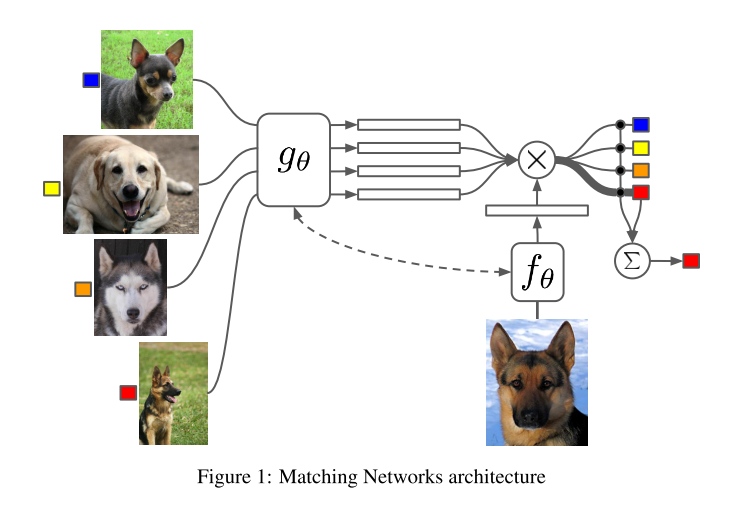
- the simplest form to compuete \(\hat{y}\) of the test example \(\hat x\): \(\hat y = \sum\limits_{i=1}^ka(\hat{x},x_i)y_i\) \(x_i\) and \(y_i\) are the samples and labels from support set, \(a\) is an attention mechanism
- the choose of attention kernel
- the simplest form is used in this paper: \(a(\hat{x},x_i)=e^{c(f(\hat{x}),g(x_j))}/\sum _{j=1}^ke^{c(f(\hat{x}),g(x_j))}\)
- \(f\) and \(g\) are embedding functions, which can be CNN for image classification task and word embedding for language task. \(c\) is the cosine distance.
- full context embeddings
- consider all the images of the support set, not just embeding one image at once. Use the bidirectional Long-Short Term Memory to encode \(x_i\) in the context of the support set.
- play the role of embedding function \(f\)
- training strategy
task \(T\) has the distribution over label set \(L\), first sample a label set \(L\) from \(T\), then use \(L\) to sample support set \(S\) and a batch \(B\)("batch" in there means queries for the given support set). training objective
\(\theta = \mathop{\arg\max}_\theta E_{L\sim T}\left[E_{S\sim L, B\sim L}\left[\sum\limits_{(x,y)\in B}\mathop{\log}P_\theta(y|x,S)\right]\right]\)
5. Evaluate
test and train conditions must match
- ran on three data sets: two image classification sets(Omniglot, ImageNet), one language model(Penn Treebank)
- Omniglot:
- Augmented the data set.
- Pick N unseen character classes, indepedent of alphabet, as \(L\), provide the model with one drawing of each of the N characters as \(S\sim L\) and a batch \(B\sim L\).
- ImageNet:
- Get three subdataset of the ImageNet: randImageNet(remove 118 labels at random from training set), dogImageNet(remove dog class), miniImageNet. Test on the three subdatasets.
6. Conclusion
- Fully Conditional Embeddings didn't seem to help much on the simple dataset, like Omniglot, but on the harder task(miniImageNet), FCE is sensible.
- one-shot learning is much easier if you train the network to do one-shot learning
- Non-parametric structures in a neural network make it easier for network to remember and adapt to new training sets in the same task.
7. Notes
- FCE consider the whole support set \(S\) instead of pair-wise comparisons.
- they tested their method trained on Omniglot on the MNIST dataset, acc about 72%
- What's the loss function of this model?
- Need to know more about FCE's details. ## 8. Reference
- O Vinyals, S Bengio, and M Kudlur. Order matters: Sequence to sequence for sets. arXiv preprint arXiv:1511.06391, 2015.

